最近在学习 MySQL 的原理,通过写文章梳理一下,先从最不熟悉的事务的隔离性开始。
逻辑架构
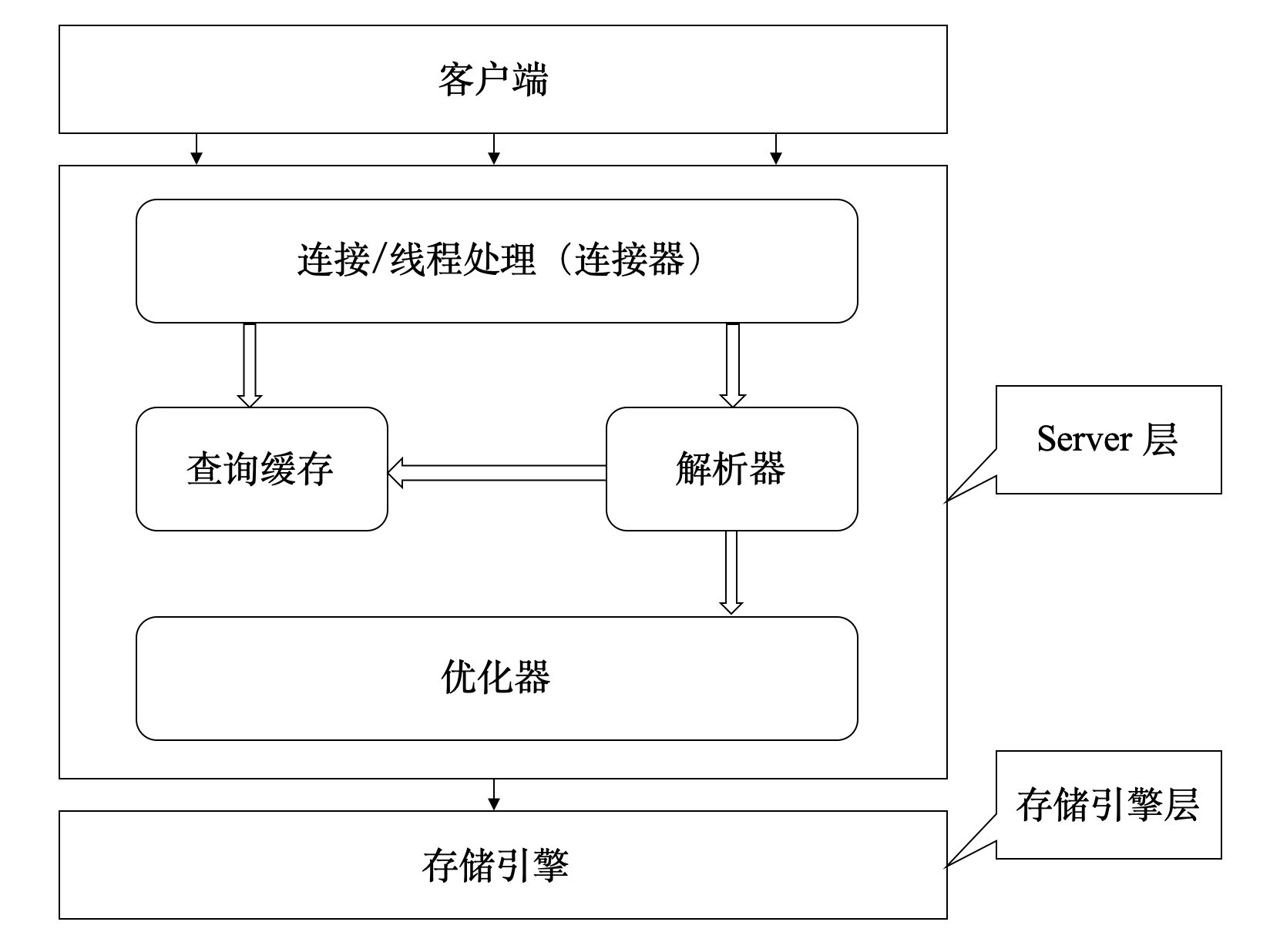
下图展示了 MySQL 的逻辑架构图,大致分为 Server 层和存储引擎层。Server 层包含 MySQL 大多数的核心服务,包括查询解析、分析、优化、缓存以及所有的内置函数(例如,日期、时间、数学和加密函数),所有跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等。存储引擎层负责 MySQL 中数据的存储和提取,其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多种存储引擎,现在最常用的存储引擎是 InnoDB(从 MySQL 5.5.5 版本开始作为默认存储引擎)。
隔离级别
事务就是一组原子性的 SQL 查询,或者说一个独立的工作单元,也就是说,事务内的语句要么全部执行成功,要么全部执行失败。MySQL 的事务是在存储引擎层实现的,默认的 MyISAM 存储引擎是不支持事务的,而 InnoDB 存储引擎支持事务,这也是 MyISAM 存储引擎被 InnoDB 取代的一个重要原因。
一个运行良好的事务处理系统,必须具备「ACID」这四个标准特征:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。其中,隔离性可能是最复杂的,在 SQL 标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做的修改,哪些在事务内和事务间是可见的,哪些是不可见的。较低级别的隔离通常可以执行更高的并发,系统的开销也更低。下面简单介绍一下四种隔离级别:
读未提交
读未提交(Read Uncommitted)级别,即使事务没有提交,其他事务也能读取到该事务中做的更新,这也被称为脏读(Dirty Read)。这个级别会导致很多问题,性能不会比其他级别好很多,但是缺乏其他隔离级别的很多好处,实际应用中一般很少使用。
读提交
大多数数据库系统(如 Oracle)的隔离级别都是读提交(Read Committed),但 MySQL 不是。在这个隔离级别下,一个事务提交前所做的任何修改对其他事务都是不可见的,没有脏读的问题,但是同一个事务中执行两次相同的查询,可能会得到不同的结果,所以这个级别有时候也叫做不可重复读(Unrepeatable Read)。
可重复读
可重复读(Repeatable Read,MySQL 的默认隔离级别)隔离级别下,在同一个事务中多次读取同样记录的结果是一致的,但是理论上还是无法解决幻读(Phantom Read)的问题。所谓幻读,指的是当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录时,就会产生幻行(Phantom Row)。InnoDB 存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)解决了幻读的问题。
串行化
串行化(Serializable)是最高的隔离级别,通过强制事务串行执行,避免幻读。简单来说,会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁争用的问题,实际应用中也很少用到这个隔离级别。
下面用一个例子演示一下,不同隔离级别下 SQL 语句的执行效果,创建一个只有一列的数据表 t,只插入一行:
create table t (c int) engine=InnoDB; |
| 事务 A | 事务 B |
|---|---|
start transaction; |
start transaction; |
select c as v0 from t; |
|
update t set c = 2; |
|
select c as v1 from t; |
|
commit; |
|
select c as v2 from t; |
|
commit; |
|
select c as v3 from t; |
- |
然后我们来看在不同的隔离级别下事务 A 会有那些不同的返回值,即 v1、v2、v3 的值都有哪些可能:
- 若隔离级别是「读未提交」,则 v1 的值就是 2。虽然事务 B 还未提交,但它做的更新已经被 A 看到了,所以 v2 和 v3 也是 2;
- 若隔离级别是「读提交」,则 v1 是 1,v2 是 2。事务 B 更新要在提交之后才能被 A 看到,所以 v3 也是 2。
- 若隔离级别是「可重复读」,则 v1 和 v2 都是 1, v3 是 2。v2 之所以是 1,是因为可重复读保证:一个事务在执行期间看到的数据前后是一致的。
- 若隔离级别是「串行化」,则在事务 B 执行更新操作时会被锁住,直到事务 A 提交后才能继续执行,所以 v1 和 v2 都是 1, v3 是 2。事务 B 之所以会被锁住,是因为在串行化隔离级别下,事务 A 会在读取的每一行数据上都加读锁,事务 B 执行更新操作时就会出现锁冲突而被阻塞。
MVCC
基于提升并发性能的考虑,MySQL 的大多数事务型存储引擎都会实现 MVCC,而不是简单的行级锁。可以认为 MVCC 是行级锁的一个变种,但是它在很多情况下避免了加锁操作,写操作也只锁定必要的行。
MVCC 是通过保存数据库在某个时间点的快照来实现的,在可重复读隔离级别下,每个事务在启动的时候会获取当前数据库一致性快照,然后整个事务的执行过程中看到的都是这份快照。在 InnoDB 存储引擎中,是通过在每行记录后面保存两个版本号实现的:行版本号和删除版本号,版本号其实就是操作这一行的事务的 ID。在可重复读隔离级别下,MVCC 具体是这样操作的:
select
InnoDB 会根据以下两个条件检查每行记录:
- 只查找行版本号小于或等于当前事务 ID 的数据行。这可以确保事务读取到的行,要么在事务开始之前就已经存在,要么是当前事务自身插入或修改过的。
- 行的删除版本号要么未定义,要么大于当前事务 ID。这可以确保事务读取到的行,在事务开始之前未被删除。
insert
InnoDB 为新插入的每一行保存当前事务的 ID 作为行版本号。
delete
InnoDB 为删除的每一行保存当前事务的 ID 作为行的删除版本号。
update
InnoDB 并不在原来的行上面更新,而是插入一行新记录,并保存当前事务的 ID 作为行版本号。同时把原来的行的删除版本号设置为当前事务的 ID。
InnoDB 为每行记录保存这两个额外的版本号,使大多数读操作都可以不用加锁,操作简单,性能很好,也能保证之后读取到符合标准的行。需要注意的是,MVCC 只在读提交和可重复读两个隔离级别下工作,其他两个隔离级别都和 MVCC 不兼容。另外,在读提交隔离级别下,每条 SQL 语句执行之前都会重新获取一致性视图,而不是只在事务启动时获取一次。下面用一个例子演示一下,创建一个有两个字段的表 t,插入两行记录:
create table t ( |
| 事务 A | 事务 B | 事务 C |
|---|---|---|
start transaction with consistent snapshot; |
||
start transaction with consistent snapshot; |
||
update t set k = k + 1 where id = 1; |
||
update t set k = k + 1 where id = 1; |
||
select k from t where id = 1; |
select k from t where id = 1; |
|
commit; |
||
commit; |
- |
先说结果:可重复读隔离级别下,这个例子中事务 A 读到的 k 值是 1,而事务 B 读到的 k 值是 3。事务 B 的表现似乎不符合可重复读的要求,其实这里用到了一个这样的规则:更新数据都是先读后写的,而这个读只能读当前最新版本的行,称为当前读(Current Read)。因为如果不读当前最新行的值,那么更新操作可能覆盖掉之前的更新,造成数据不一致。而事务 B 更新之后再进行查询,按照前面说的 select 的规则是能够查询到最新值 3 的。
其实除了 update 语句外,select 语句如果加锁,也是当前读,如果把事务 A 的 select 语句改成下面两个(分别加读锁和写锁)之一,也能读到最新值 3:
select k from t where id = 1 lock in share mode; |
再进一步,如果事务 C 执行 update 后没有马上提交,这时事务 B 又发起了 update 操作,会怎样呢?这个时候 k 的最新值已经是 2 了,但是由于事务 C 还没有提交,所以最新版本上的行锁没有释放。而事务 B 的更新操作是当前读,必须读到最新版本且必须加锁,所以事务 B 的更新操作被阻塞,直到事务 C 提交后释放行锁。