Algorithm
这周做的是一道 腾讯精选练习 50 题 中的简单题 有效的括号,这题非常简单:使用一个栈存储左括号,遇到右括号时弹栈,看是否是匹配的左括号,处理完输入的字符串以后,如果栈是空的说明字符串是题目中定义的有效的。
class Solution { |
Review
这周读了 Spark SQL 论文《Spark SQL: Relational Data Processing in Spark》的前半部分,Spark SQL 是 Spark 的一个库(如下图所示),可以把 SQL 或者使用 DataFrame API 编写的实现类似 SQL 查询的(Java、Scala 或者 Python)代码编译成操作 RDD(Resilient Distributed Datasets)的字节码,然后在 Spark 框架上运行。
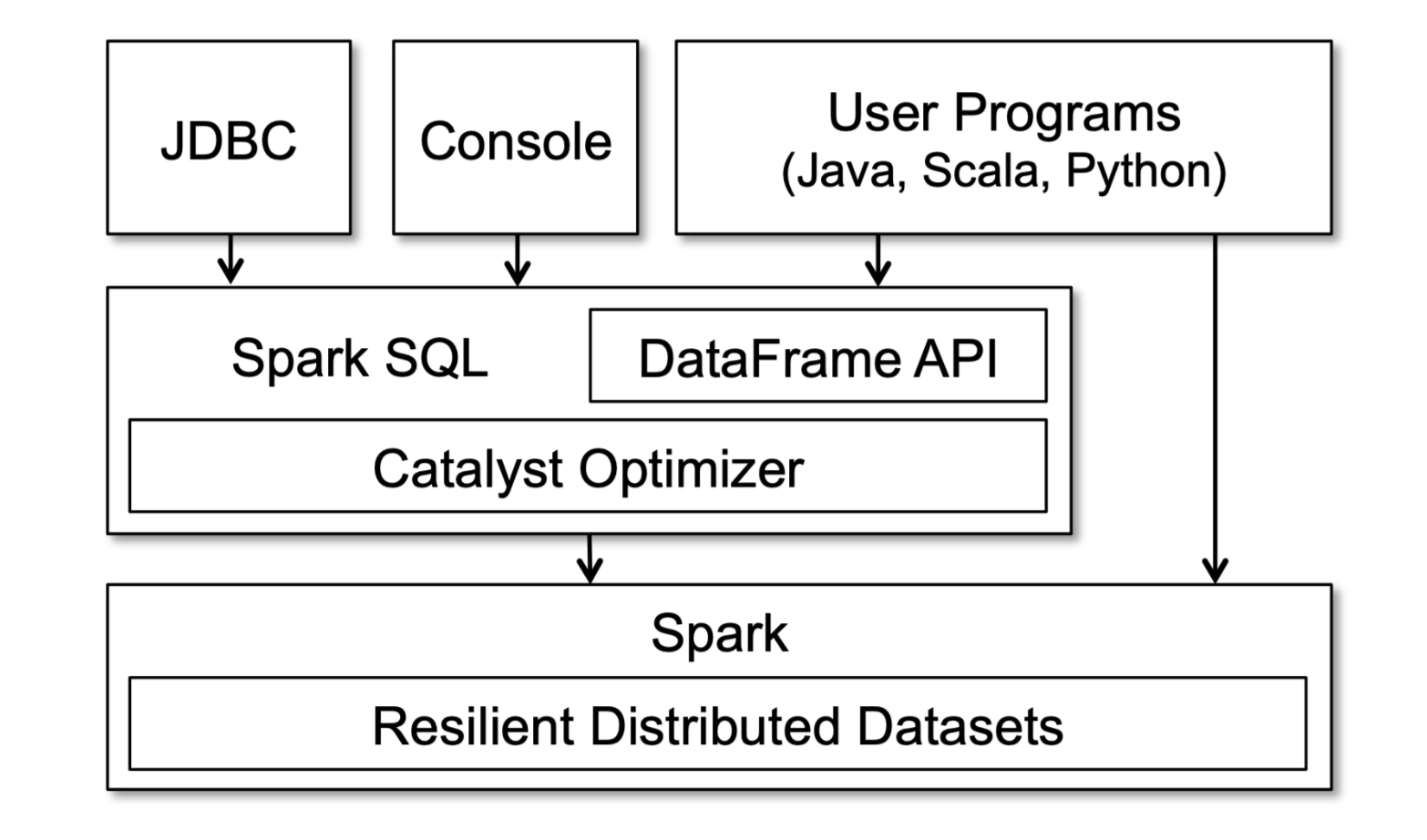
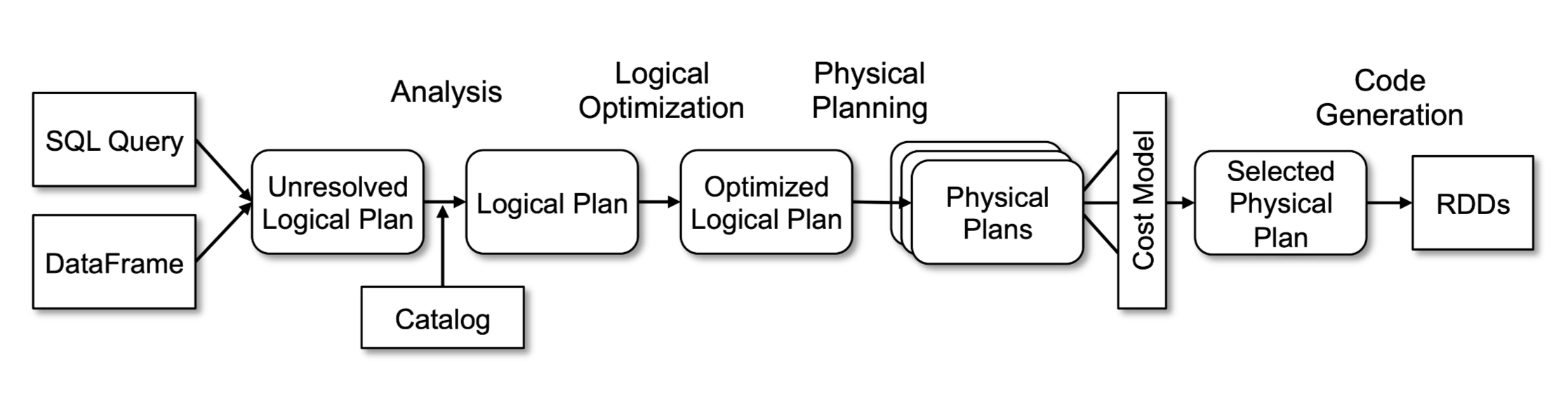
函数式编程语言非常适合用来实现编译器,Spark SQL 也用了 Scala 的很多特性,如:Pattern Matching、Quasiquotes 等,来简化编译、优化部分的代码。我更在意的其实是 Spark SQL 和元数据的交互,下图中的 Analysis 阶段会查询元数据做确认字段是否存在、字段的类型等工作,通过读论文大致了解了 Spark SQL 的架构。
Tip
工作中经常会用到线程池,一般是把一个大的任务拆解到每个线程中执行,需要等待所有线程运行完才能进行后续的操作,shutdown() 方法并不会等待所有线程执行完毕,只是不再接受新任务而已,需要配合 awaitTermination() 使用。当然考虑到创建线程池的开销,下面的方法只适合那种一次性的任务,如果是一个持续运行的 JVM 进程,考虑使用 CountDownLatch 等来可控制。
public class TestExecutorService { |
Share
最近看到 Hive 的事务实现的时候,突然心生疑惑:为什么已经有类似 MVCC(Multi-Version Concurrency Control)的机制了,还需要锁呢 ?之前也研究过 MySQL 的事务,但是并没有深入思考过,今天又查了一些资料,虽然还是有很多盲点,但是想通了几个问题,先记录一下。
MVCC 解决的主要是读的效率问题,如果没有 MVCC,那并发控制就是通过读写锁实现的:某一行记录如果加了写锁,其他事务对这行的读操作就会被阻塞。有了 MVCC 之后,即使某一行被其事务加了写锁,也可以进行快照读,读这一行的某个版本。但需要注意的是,即使有了 MVCC,对某一行的写操作还是要加写锁的,这是正常的并发控制的要求,防止同时写一行记录造成不一致。
MVCC 在读提交和可重复读隔离级别下起作用,两种隔离级别下启动事务的时候都会创建一致性视图,不同的是:在可重复读隔离级别下,主要在事务开始的时候创建一致性视图,之后事务里的其他查询共用这个一致性视图;而在读提交隔离级别下,每一个语句执行前都会重新算出一个新的视图,可以看下面的例子:
create table t ( |
| 事务 A | 事务 B | 事务 C |
|---|---|---|
start transaction with consistent snapshot; |
||
start transaction with consistent snapshot; |
||
update t set k = k + 1 where id = 1; |
||
update t set k = k + 1 where id = 1; |
||
select k from t where id = 1; |
select k from t where id = 1; |
|
commit; |
||
commit; |
- |
在可重复读隔离级别下,事务 A 读到的 k 的值是 1,这个基于一致性视图很容易理解;但是事务 B 读到的 k 的值是 3,因为读之前有个更新的操作,更新操作都是先读再更新的,这个读是当前读,读的是这行最新的值,如果还是一致性读,事务 C 的更新就会丢失,同一个事务中的更新对后面的读操作是可见的,所有读到的 k 值是 3。
在读提交隔离级别下,事务 B 读到的 k 值还是 3,但是事务 A 读到的 k 值变成 2 了,因为每一个语句执行前都会计算一致性视图,事务 A 读取的时候事务 C 已经提交了,所以读到的 k 值是 2。